# 概述
什么是 NeRF?是输入一堆二维的 RGB 图片以后直接输出一个通过多边形网格(Mesh)构建的三维模型吗?
并非如此。具体的讲,它其实是一个从像素到像素的连续函数拟合过程。它不显式地存储点云或网格,而是把整个场景的颜色和密度信息“压缩”到了一个神经网络的权重里。
整个过程的简要数据流向如下:
像素坐标 (Pixel) 光线生成 (Ray Casting) 采样与编码 (Sampling & Encoding) 神经网络 (MLP) 体渲染 (Volume Rendering) 预测颜色 (Predicted Color)
# 1. 核心定义
NeRF 的核心思想非常简洁:它认为三维世界可以表示为一个连续的函数 。
你只要告诉这个函数你在哪里(空间位置 ),往哪看(视角方向 ),它就能告诉你那个点是什么颜色 ,以及那个点有多浓密(体密度 )。
数学公式表示为:
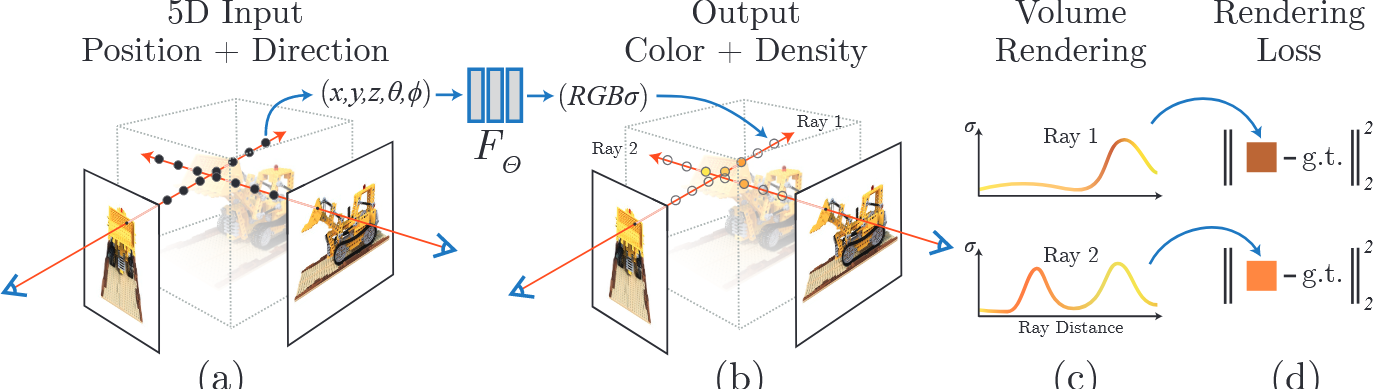
- 输入 (5D):空间坐标 + 视角方向
- 输出 (4D):颜色 + 体密度
# 2. NeRF 的 WorkFlow
NeRF 的训练过程本质上是一个“逆向渲染”的过程。我们有一堆已经拍好的照片(Ground Truth),我们希望训练一个网络,让它渲染出来的图片和真实照片一模一样。
# 第一步:光线生成 (Ray Generation)
从 2D 像素反推 3D 射线
我们在屏幕上看到的每一个像素,其实都是从相机光心发出的一条射线,穿过屏幕像素点,射向三维空间。
- 原理:利用相机内参()和外参(),将图像平面的像素坐标 转换为世界坐标系下的射线。
- 射线方程:,其中 是射线原点(相机位置), 是射线方向。
# 第二步:沿射线采样 (Sampling)
把连续射线离散化
计算机无法处理无限连续的射线,所以我们需要在射线上“撒点”。
- 粗采样 (Coarse Sampling):在相机的近平面 (near) 和远平面 (far) 之间,随机采样 个点(例如 64 个)。
- 随机性:为了让网络学习到连续空间的信息,采样点的位置通常带有随机扰动,防止过拟合到固定的栅格上。
# 第三步:位置编码 (Positional Encoding)
强行“升维”,捕捉高频细节
神经网络(MLP)天生存在“低频偏差”,倾向于学习平滑的信号,导致渲染结果模糊。为了解决这个问题,NeRF 在将坐标 喂给网络之前,先通过 和 函数将其映射到高维空间。
- 通过这种高频函数的映射,微小的位置变化会被放大,使得网络能够捕捉到纹理、边缘等高频细节。
- 实验表明,没有这一步,NeRF 无法重建清晰的场景细节。
# 第四步:神经网络预测 (MLP Inference)
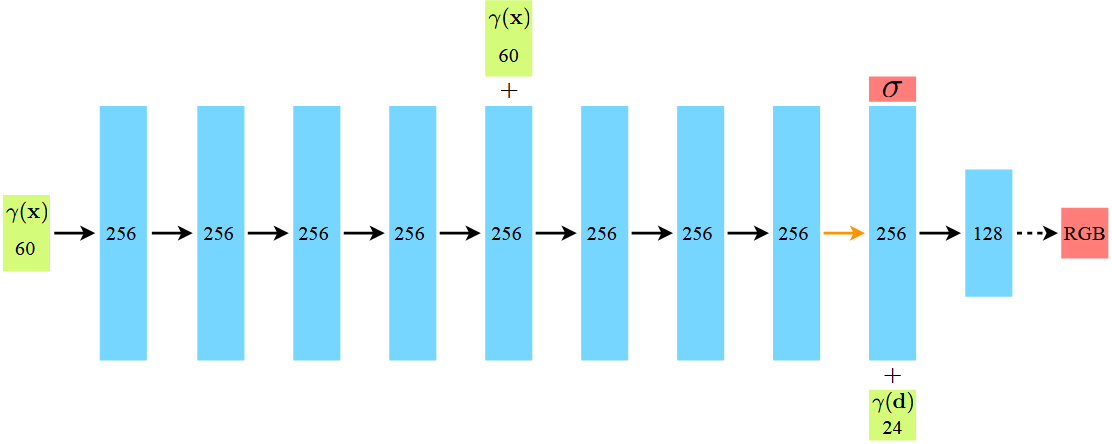
将编码后的采样点位置和方向输入到一个全连接神经网络(MLP)中。
- 网络输出该点的 RGB 颜色 和 体密度 。
- 注意:密度 只与位置有关(物体结构是固定的),而颜色 与位置和视角都有关(模拟高光和反射)。
# 第五步:体渲染 (Volume Rendering)
积分成色
拿到射线上所有采样点的颜色和密度后,利用光线传输方程(RTE)的离散形式,计算出这条射线最终在相机上成像的颜色。
- (透射率):代表光线到达当前点之前没有被遮挡的概率。如果前面的点密度很高,光线就被挡住了, 就会接近 0。
- :代表当前点的不透明度(Alpha 值)。
- 物理直觉:这就是一个加权求和的过程。颜色权重大,说明这里不透明且没被遮挡;权重小,说明这里是透明的(空气)或者被前面的物体挡住了。
# 第六步:计算 Loss 与优化
让预测逼近真实
将渲染出的预测颜色 与真实照片中对应像素的颜色 进行对比,计算均方误差(MSE Loss):
由于整个渲染过程都是可微的(Differentiable),我们可以直接通过反向传播(Backpropagation)更新 MLP 的权重,让它“记住”这个场景。
# 3. 进阶优化:层次化采样 (Hierarchical Sampling)
为了提高效率,NeRF 实际上使用了“粗网络”和“细网络”两个模型:
- 先用粗网络在射线上稀疏采样,通过计算出的权重分布,找到物体真正存在的区域(密度大的地方)。
- 在这些重要区域进行加密采样(Fine Sampling),放入细网络进行更精细的渲染。
- 这就像是“先大致看一眼哪有东西,再凑近了仔细看”,既节省了计算资源,又保证了细节质量。
# 总结
NeRF 的本质是一个通过 MLP 隐式存储的 5D 场。它不需要保存庞大的点云数据,只需要保存几 MB 的网络权重。通过位置编码解决高频细节问题,通过体渲染实现可微训练,NeRF 为 3D 视觉合成开辟了一个全新的方向。
